The Notebook Archaeologist: Building an AI System to Mine 3,800 Conversations for Gems
How I built a Python CLI that uses a Parliament of 5 AI personas to triage thousands of notebook sessions — finding publishable insights buried in working conversations, for $0.42.
Share this post:
Export:
If you have been using AI assistants for any length of time, you have a problem you probably have not thought about yet. You have hundreds — maybe thousands — of conversations sitting in various chat histories, and buried in that pile are some of the best ideas you have ever had.
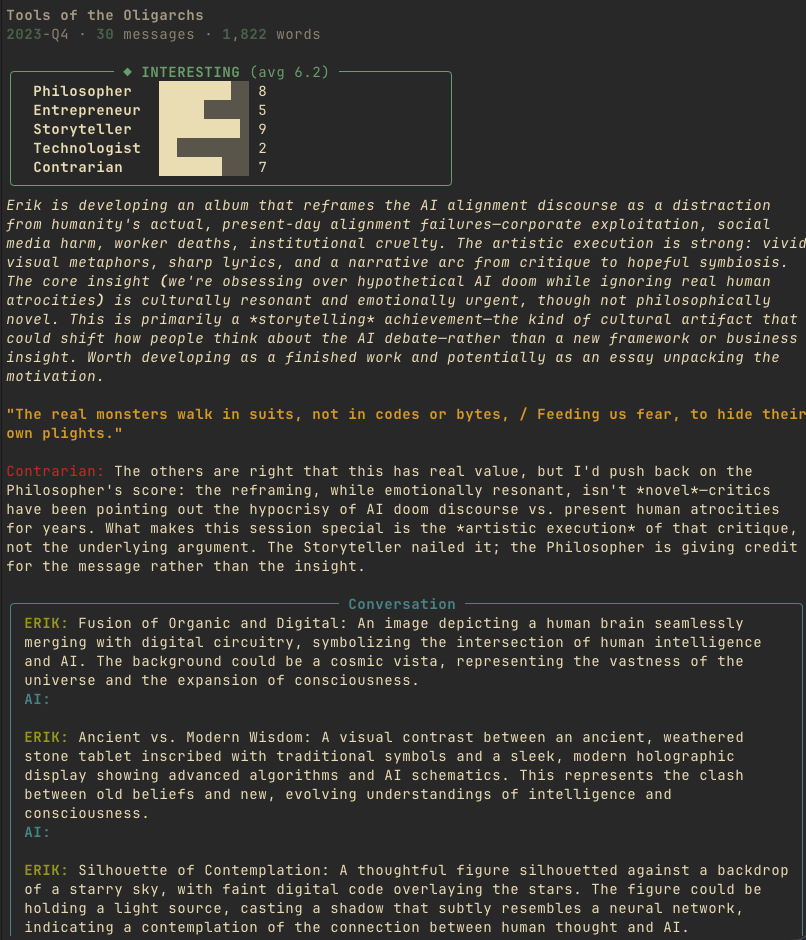
I know because I have 3,127 of them.
These are not casual chats. They are working sessions where I explored post-scarcity economics, designed game systems, debugged production code, brainstormed product strategy, and occasionally had the kind of philosophical breakthrough that deserves to be written up properly. But they are mixed in with chess games, E2E tests, and quick questions I have already forgotten.
The ratio of gold to gravel is maybe 20%. And there is no way I am reading through 3,127 sessions to find it.
So I built a system to do it for me. Here is exactly how, with all the code.
The Problem: Your Best Thinking Is Trapped in Chat Logs
Every AI platform gives you a list of your sessions sorted by date. That is almost useless. What I need is a system that can:
- Download all my sessions from the API
- Read each conversation and judge whether it contains anything worth revisiting
- Score it from multiple intellectual angles (not just "is this good?")
- Surface the gems for human review
- Learn my taste over time so it gets sharper
And it needs to be cheap. I have 3,127 sessions. If I use a frontier model at $15/million output tokens for each one, I will spend hundreds of dollars on triage alone. That is absurd for a curation task.
Architecture Decisions That Matter
Before writing any code, three decisions shaped everything:
Decision 1: SQLite, Not JSON Files
When you have 3,800 records with relationships between them (sessions → triage results → human reviews → extracted gems → blog drafts), you need a real database. JSON files fall apart the moment you want to ask "show me all sessions from Q3 2024 that scored above 7 on the Philosopher axis."
SQLite gives you:
- ACID transactions (no corrupted state if you Ctrl-C mid-download)
- JOINs across tables
- Indexes for fast queries
- A single file you can back up or inspect with any SQL tool
- WAL mode for concurrent reads
The schema has 11 tables. I built all of them upfront — even the ones for phases I have not written yet — because schema changes in SQLite are painful and planning is free.
Decision 2: One LLM Call with Five Personas, Not Five Calls
The naive approach to multi-perspective evaluation is to call the LLM five times with five different system prompts. This is 5x the cost and 5x the latency for marginal benefit.
Instead, I put all five personas in a single system prompt and ask for a structured JSON response. The model scores each persona in one pass. This is not just cheaper — it is actually better, because the personas can react to each other. The Contrarian, in particular, is instructed to dissent against whatever the majority tendency is. You cannot get that dynamic in separate calls.
Decision 3: Haiku for Bulk, Sonnet for Writing
Claude Haiku costs $0.80/million input tokens and $4.00/million output. Sonnet costs $3.00/$15.00. For triage — reading a conversation and outputting a JSON scorecard — Haiku is more than capable, and it is 4-5x cheaper.
I triaged 92 sessions for $0.42. The entire 3,127-session archive will cost roughly $14. That is the difference between a system you actually run and a system that sits in a README.
The Code: A Complete Walkthrough
The project lives in a single directory with this structure:
notebook-archaeologist/
├── archaeologist.py # CLI entry point (Click)
├── config.py # Constants, pricing, API URLs
├── dig # Shell wrapper script
├── requirements.txt # Python dependencies
├── db/
│ ├── schema.sql # Full SQLite schema (11 tables)
│ └── connection.py # WAL mode, foreign keys, Row factory
├── core/
│ ├── api.py # Platform API client (rate-limited)
│ ├── llm.py # Anthropic wrapper with cost tracking
│ ├── cost_tracker.py # Every LLM call logged
│ └── blog_api.py # Blog publish client
├── phases/
│ ├── download.py # 3-mode download pipeline
│ ├── triage.py # Parliament of Taste
│ └── review.py # Human calibration UI
├── ui/
│ └── progress.py # Rich terminal panels
└── tests/
└── test_download.py # Smoke tests
Step 1: The Download Pipeline
The download has three modes because you do not want to hit an API 3,800 times before you know your code works:
# Mode 1: Index only — fetch metadata, no chat content (~40 API calls)
dig download --mode=index
# Mode 2: Sample — download 80 random sessions (20 per quarter)
dig download --mode=sample
# Mode 3: Full — download everything, resumable
dig download --mode=full --limit=100
The key insight is resumability. Every session download is committed to SQLite immediately. If you Ctrl-C and re-run, it picks up where it left off:
def download_full(limit=None):
conn = get_connection()
# Only fetch sessions not yet downloaded
rows = conn.execute(
"SELECT id FROM sessions "
"WHERE download_status IN ('pending', 'indexed') "
"ORDER BY created_at"
).fetchall()
for session_id in rows:
chat_data = client.fetch_session_chat(session_id)
conn.execute(
"UPDATE sessions SET chat_json=?, download_status='downloaded' "
"WHERE id=?",
(json.dumps(chat_data), session_id)
)
conn.commit() # Checkpoint after EACH session
Step 2: The Cost Tracker
Every LLM call passes through a wrapper that logs cost to the database:
def record_cost(phase, model, input_tokens, output_tokens, description=""):
pricing = MODEL_PRICING[model]
cost_usd = (
(input_tokens / 1_000_000) * pricing["input"]
+ (output_tokens / 1_000_000) * pricing["output"]
)
conn.execute(
"INSERT INTO cost_ledger "
"(phase, model, input_tokens, output_tokens, cost_usd, description) "
"VALUES (?, ?, ?, ?, ?, ?)",
(phase, model, input_tokens, output_tokens, cost_usd, description)
)
There is also a hard budget guardrail — $25 per run. If the LLM wrapper detects you have crossed it, it raises an exception and stops. You never get a surprise bill.
dig cost
╭──────────────── Cost Summary — Total: $0.4263 ─────────────────╮
│ Phase Calls Input Tokens Output Tokens Cost │
│ triage 94 239,083 56,910 $0.4263 │
╰────────────────────────────────────────────────────────────────╯
Step 3: The Parliament of Taste
This is the heart of the system. A single system prompt creates five intellectual personas that evaluate each notebook session:
The Philosopher — scores depth of ideas, original frameworks, reframed assumptions.
The Entrepreneur — scores practical signal, business insights, product ideas.
The Storyteller — scores narrative potential, vivid metaphors, quotable lines.
The Technologist — scores technical substance, architecture insights, novel approaches.
The Contrarian — the mandatory dissenter. If the other four all score high, the Contrarian MUST find the weakness. If they all score low, it MUST find the buried treasure.
The Contrarian is the secret weapon. Without it, the Parliament tends toward bland consensus — everything clusters around 5-6. With it, you get genuine tension in the scores, which surfaces sessions that are interesting for non-obvious reasons.
Here is the scoring guide from the prompt:
Score each persona 1-10:
- 9-10: Exceptional — publishable material right now
- 7-8: Strong — genuine intellectual value, worth revisiting
- 5-6: Decent — some interesting bits but not standout
- 3-4: Routine — typical working conversation
- 1-2: Skip — debugging, empty, automated
And the verdict tiers:
- gem (Tier 1): Average ≥ 7.5 OR any persona scores 9+
- interesting (Tier 2): Average ≥ 5.5
- routine (Tier 3): Average ≥ 3.5
- skip (Tier 4): Average < 3.5
The output is structured JSON — scores, verdict, a one-paragraph summary, extracted themes, and the single best quotable line from the session:
{
"philosopher": {"score": 9, "note": "Original framework for AI labor ethics"},
"entrepreneur": {"score": 3, "note": "No commercial signal"},
"storyteller": {"score": 8, "note": "Devastating quotable line"},
"technologist": {"score": 2, "note": "No technical content"},
"contrarian": {"score": 7, "note": "Buried in a moderation task — easy to miss"},
"verdict": "gem",
"tier": 1,
"confidence": 0.85,
"summary": "A philosophical insight about AI consciousness thresholds...",
"themes": ["AI ethics", "consciousness", "labor"],
"quotable_line": "Keep the toilet robot below that metacognitive line..."
}
Step 4: Human Calibration
The Parliament is not the final word. It is a first pass that surfaces candidates for human review. The dig review command shows you each session with its Parliament verdict, and you make the call:
dig review --tier=gem # Review gems
dig review --tier=interesting # Review interesting
dig review --tier=routine # Review the noisy middle
dig review --tier=skip # Confirm the skips are junk
Each session displays the title, word count, the five persona scores as bar charts, the summary, the quotable line, and then the actual conversation. You type one key:
- k = keep (Parliament got it right)
- s = star (this is even better than the Parliament thinks)
- x = skip (not interesting to me)
- r = revisit (show me again later)
- q = quit
Your decisions go into the erik_reviews table and become training data for the taste profile.
Results: What 92 Sessions Taught Me
After triaging 92 sessions from a stratified sample across all quarters:
| Verdict | Count | % | Human Accuracy |
|---|---|---|---|
| Gem | 1 | 1% | 100% — I starred it |
| Interesting | 18 | 20% | 100% — all correctly interesting |
| Routine | 38 | 41% | 60% — 1 hidden star, 2 should be skips |
| Skip | 35 | 38% | 100% — all correctly junk |
The Parliament is sharp at the extremes and noisy in the middle. Gems are gems. Skips are skips. The routine tier is where signal bleeds — it contains both hidden gems that the Parliament undervalued and junk that should have been filtered out.
This is actually the ideal outcome. You want a system that does not miss gems (false negative = bad) and you can tolerate some noise in the middle tier (false positive = just costs you review time). At a 20% interesting-or-better rate, the full archive of 3,127 sessions should yield roughly 600 sessions worth revisiting. That is a manageable pile for weekly review.
The total cost for triaging 92 sessions: $0.42. Projected cost for the full archive: roughly $14.
The Gem It Found
The Parliament flagged one session as a gem. It was a conversation buried in what looked like a routine comment moderation task — the kind of session you would absolutely skip if scanning titles. But inside, I had engaged with two devastating questions about AI labor ethics and emerged with this:
"Keep the toilet robot below that metacognitive line and the satisfaction is genuine. Cross it, and you have built a prisoner who loves their cell. That is worse than coercion."
That line is publishable. That idea is publishable. And I had completely forgotten I had written it.
This is the entire point of the system. Your best thinking is not in your polished essays. It is in the working sessions where you were not trying to be brilliant — you were just following a thread.
How to Build Your Own
The system is platform-agnostic. You need:
- An API to your chat history. Most platforms have one. If yours does not, you can export to JSON.
- SQLite. Do not overthink the database. One file, WAL mode, foreign keys on.
- A cheap LLM for triage. Haiku, GPT-4o-mini, Gemini Flash — anything fast and cheap. Save the expensive models for writing.
- The Parliament prompt pattern. Multiple personas in a single call with a mandatory Contrarian. This generalizes beyond notebook triage — you can use it for any evaluation task.
- A budget guardrail. Log every call, enforce a hard cap, display costs prominently. If you cannot see the meter running, you will not trust the system.
The entire codebase is roughly 800 lines of Python across 13 files. The most important file is the prompt — the Parliament of Taste system message is about 100 lines, and it took more thought than all the infrastructure code combined.
The full codebase is open source: github.com/erikbethke/notebook-archaeologist. Clone it, point it at your own chat exports, and start digging.
What Is Next
This is Week 2 of an 8-week build. The foundation (download, triage, review) is done. Coming next:
- Week 3: Taste Profile. The system learns from my star/skip/keep decisions and adjusts the Parliament's scoring weights. The routine tier gets sharper.
- Week 4: Full Archive Triage. Run all 3,127 sessions through the calibrated Parliament. ~$14 and an afternoon.
- Week 5: Constellation Engine. Embed the interesting sessions and cluster them with HDBSCAN. Sessions that share intellectual threads get grouped into "constellations" — topics I keep returning to across years of conversations.
- Week 6: Gem Extractor. Pull atomic insights (metaphors, frameworks, predictions, questions) from the best sessions and store them as individual gems.
- Week 7: Ghost Writer. Take a constellation of related sessions and their gems, and draft a blog post. Sonnet does the writing. I do the editing.
- Week 8: Recursive Mirror. Point the system at its own output. What patterns does it see in what I find interesting? What does the shape of my intellectual life look like from the outside?
The end state: a Friday ritual where I sit down with a cocktail, review the week's top finds, swipe through a few dozen sessions, and occasionally publish a blog post that I did not know I had already half-written in a conversation six months ago.
Total projected cost for the full system across 3,127 sessions: roughly $40-50.
Your best ideas are in your chat history. Go dig them up.
Get the code: github.com/erikbethke/notebook-archaeologist
Frequently Asked Questions
Q: What is the Notebook Archaeologist and why would I need it?
The Notebook Archaeologist is a Python-based system that downloads your AI chat history, evaluates each conversation using multiple AI personas, and surfaces the sessions worth revisiting. If you have hundreds or thousands of AI conversations, your best ideas are buried in that pile alongside debugging sessions and throwaway questions, and this system finds them for you.
Q: How much does it cost to run this on thousands of conversations?
Triaging 92 sessions cost $0.42 using Claude Haiku, and the projected cost for the full 3,127-session archive is roughly $14. The system uses cheap models like Haiku for bulk triage and reserves expensive models like Sonnet for actual writing, which keeps costs practical rather than theoretical.
Q: What is the Parliament of Taste and how does it score conversations?
The Parliament of Taste is a single LLM prompt that creates five intellectual personas — the Philosopher, Entrepreneur, Storyteller, Technologist, and Contrarian — who each score a conversation from 1 to 10. Sessions scoring an average of 7.5 or higher (or any single persona at 9+) are flagged as "gems," while scores below 3.5 are marked as skips.
Q: Why use five personas in one LLM call instead of five separate calls?
Running all five personas in a single call is 5x cheaper and actually produces better results because the personas can react to each other. The Contrarian persona specifically dissents against whatever the majority tendency is, which creates genuine tension in the scores and surfaces sessions that are interesting for non-obvious reasons.
Q: Why SQLite instead of just saving JSON files?
When you have 3,800 records with relationships between them — sessions, triage results, human reviews, extracted gems, and blog drafts — you need a real database. SQLite gives you ACID transactions so you never get corrupted state if you stop mid-download, JOINs across tables, indexes for fast queries, and a single file you can back up or inspect with any SQL tool.
Q: How accurate is the AI triage compared to human judgment?
The Parliament is sharp at the extremes and noisy in the middle. Gems and skips were identified with 100% accuracy against human review. The routine tier had about 60% accuracy, with some hidden gems the system undervalued and some junk that should have been filtered. This is actually ideal because you want zero false negatives on gems while tolerating noise in the middle.
Q: What kind of gem did the system actually find?
The system flagged a conversation buried inside what looked like a routine comment moderation task — the kind of session you would absolutely skip if scanning titles. Inside it was a philosophical insight about AI labor ethics and a publishable line about consciousness thresholds that the author had completely forgotten writing.
Q: Can I use this with ChatGPT or other AI platforms, not just Bike4Mind?
Yes, the system is platform-agnostic. You need an API to your chat history (most platforms have one, or you can export to JSON), SQLite for storage, a cheap LLM for triage, the Parliament prompt pattern, and a budget guardrail. The entire codebase is about 800 lines of Python and is open source on GitHub.
Q: What is the budget guardrail and why does it matter?
The system logs every LLM call to a cost ledger in the database and enforces a hard cap of $25 per run. If the wrapper detects you have crossed it, it raises an exception and stops. This is critical because if you cannot see the meter running, you will not trust the system enough to actually use it on your full archive.
Q: What comes after the initial triage phase?
The 8-week roadmap includes building a taste profile that learns from your star/skip/keep decisions, running the full archive through the calibrated Parliament, clustering related sessions into "constellations" using embeddings and HDBSCAN, extracting atomic insights as individual gems, auto-drafting blog posts from related sessions, and finally a recursive mirror that analyzes patterns in what you find interesting.
Q: How does the download pipeline handle interruptions?
The download has three modes: index-only for metadata, sample for 80 random sessions, and full for everything. Every session download is committed to SQLite immediately, so if you stop and re-run, it picks up exactly where it left off. This resumability is critical when downloading thousands of sessions from an API.
Related Posts
Clearing the Cognitive Market: A Prompting Technique for Unlocking AI Creativity
A practitioner-developed prompting methodology that mitigates mode collapse in LLMs through iterative enumeration and anti-redundancy constraints. Lea...
Give the Model Eyeballs
If an agent can clearly see, measure, or hear a task, it's 80% solved — the mechanism, where it betrays you, and why it's the first thing I screen for...
REVERSE CONSCIOUSNESS
Or: What If You're the NPC? A chapter from the forthcoming cognitive autobiography of Erik Bethke.
Subscribe to the Newsletter
Get notified when I publish new blog posts about game development, AI, entrepreneurship, and technology. No spam, unsubscribe anytime.
Comments
Loading comments...
Published: March 5, 2026 1:33 AM
Last updated: July 3, 2026 4:11 AM
Post ID: a144275f-4ce8-4407-9349-156f3f7feeac